Research interests and activities
My research interests and activities can roughly be grouped into these topics; for guidance, I am taking inspiration from research into human learning, especially developmental learning during infancy.
- Scalable incremental/continual learning
- High-dimensional data description by Deep Gaussian Mixture Models
- Object detection in context
Scalable incremental learning
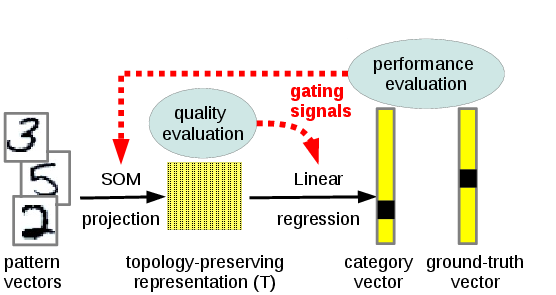
- efficient for problems of very high dimensionality (>1000)
- scalable, with constant time complexity w.r.t. already learned knowledge
- at least partially generative
Deep Convolutional Gaussian Mixture Models
This endeavor is related to my research on continual learning, which must, to my mind, necessarily contain an element of replay. However, the standard way of achieving this through GANs has its problems, which stems from the fact that GANs do not have an associated loss function, so there is no way to know whether a GAN is currently undergoing mode collapse, a frequent problem. Replacing GANs by GMMs as generators would be the ideal solution; however the quality of sampling from vanilla GMMs is strongly inferior to GANs. Therefore, I am looking for ways to create stacked convolutional variants of GMMs that can leverage the inherentA first prominent result of these activities is an SGD-based training algorithm for GMMs that works for lage sets of natural images and it superior, both in performance and manageability, to sEM, a stochastic version of EM, the usual training algorithm for GMMs.
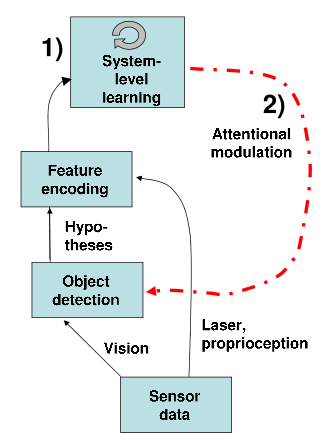
Object detection in context
|

|
What interests me currently is the question of how to learn situation-specific context models. As a very obvious example, consider the search for pedestrians in inner-city and highway traffic: while in the former case one might have to look preferentially at the sidewalk, while in the latter case one does not look for pedestrians at all since they are rarely encountered on highways. Recently, I have studied how Gaussian Mixture Models(GMMs) can be used to learn this kind of correlation in an autonomous fashion.